We can use databases to store and manage structured datasets, but that is not enough for analysis and decision-making. Linux Hint LLC, [emailprotected]
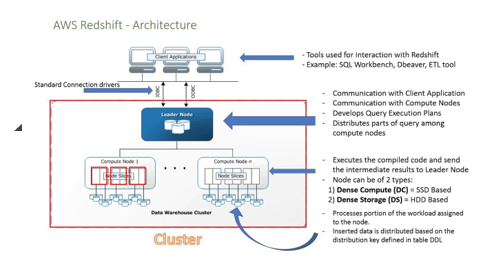
Redshift operates in a clustered model with a leader node, and multiple worked nodes, like any other clustered or distributed database models in general. To avoid additional costs, we will use the free tier type for this demonstration purposes. A superuser has admin rights to a cluster and bypasses all permission checks. 
 Firstly, provide a cluster name of your choice. takes about one hour. ), Marketo to PostgreSQL: 2 Easy Ways to Connect, Pardot to BigQuery Integration: 2 Easy Ways to Connect. By using Groups, you separate your workloads from each other. I write about the process of finding the right WLM configuration in more detail in 4 Simple Steps To Set-up Your WLM in Amazon Redshift For Better Workload Scalability and our experience withAuto WLM. Next, we need to select the Cluster identifier, Database name, and Database user. Thats because nobody ever keeps track of those logins. Weve found that a cluster with the correct setup runs faster queries at a lower cost than other major cloud warehouses such as Snowflake and BigQuery. They use one schema per country. These methods, however, can be challenging especially for a beginner & this is where Hevo saves the day. Out of which, one node is configured as a master node which can manage all the other nodes and store the queried results. Each cluster runs an Amazon Redshift engine.
Firstly, provide a cluster name of your choice. takes about one hour. ), Marketo to PostgreSQL: 2 Easy Ways to Connect, Pardot to BigQuery Integration: 2 Easy Ways to Connect. By using Groups, you separate your workloads from each other. I write about the process of finding the right WLM configuration in more detail in 4 Simple Steps To Set-up Your WLM in Amazon Redshift For Better Workload Scalability and our experience withAuto WLM. Next, we need to select the Cluster identifier, Database name, and Database user. Thats because nobody ever keeps track of those logins. Weve found that a cluster with the correct setup runs faster queries at a lower cost than other major cloud warehouses such as Snowflake and BigQuery. They use one schema per country. These methods, however, can be challenging especially for a beginner & this is where Hevo saves the day. Out of which, one node is configured as a master node which can manage all the other nodes and store the queried results. Each cluster runs an Amazon Redshift engine. 

 The challenge is to reconfigure an existing production cluster where you may have little to no visibility into your workloads. redshift security spectrum emr node note master name Users in the Transform category read from the raw schema and write to the data schema. Assign the load user group to this queue. He has worked internationally with Fortune 500 clients in various sectors and is a passionate author. All users in the transform category. No more slow queries, no more struggling with data, lower cost. You can rename that db to something else, e.g. Provide the details as shown below and click on Connect to database button. redshift mcamis
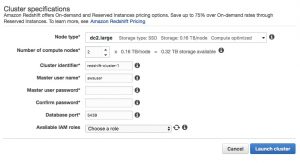
The challenge is to reconfigure an existing production cluster where you may have little to no visibility into your workloads. redshift security spectrum emr node note master name Users in the Transform category read from the raw schema and write to the data schema. Assign the load user group to this queue. He has worked internationally with Fortune 500 clients in various sectors and is a passionate author. All users in the transform category. No more slow queries, no more struggling with data, lower cost. You can rename that db to something else, e.g. Provide the details as shown below and click on Connect to database button. redshift mcamis  When using IAM, the URL (cluster connection string) for your cluster will look like this: jdbc:redshift:iam://cluster-name:region/dbname. In their report Data Warehouse in the Cloud Benchmark, GigaOM Research concluded that Snowflake is 2-3x more expensive than Redshift. Provide a password of your choice as per the rules mentioned below the password box. Now lets look at how to orchestrate all these pieces. AWS Redshift is a columnar data warehouse service on AWS cloud that can scale to petabytes of storage, and the infrastructure for hosting this warehouse is fully managed by AWS cloud.
When using IAM, the URL (cluster connection string) for your cluster will look like this: jdbc:redshift:iam://cluster-name:region/dbname. In their report Data Warehouse in the Cloud Benchmark, GigaOM Research concluded that Snowflake is 2-3x more expensive than Redshift. Provide a password of your choice as per the rules mentioned below the password box. Now lets look at how to orchestrate all these pieces. AWS Redshift is a columnar data warehouse service on AWS cloud that can scale to petabytes of storage, and the infrastructure for hosting this warehouse is fully managed by AWS cloud.  To run the query, you need to connect with some Redshift cluster. Once the cluster is created you would find it in Available status as shown below. You can focus on optimizing individual queries. And its also the approach you can and should! redshift account aws data spectrum query encrypted kms enable cross copy cluster following name Hevo, with its strong integration with 100+ sources & BI tools, allows you to not only export & load data but also transform & enrich your data & make it analysis-ready in a jiff. This Redshift supports creating almost all the major database objects like Databases, Tables, Views, and even Stored Procedures. View all posts by Rahul Mehta, 2022 Quest Software Inc. ALL RIGHTS RESERVED. Queues and the WLM arethe most important conceptsfor achieving high concurrency. When you click on the Run button, it will create a table named Persons with the attributes specified in the query. This is generally not the recommended configuration for production scenarios, but for first-time users who are just getting started with Redshift and do not have any sensitive data in the cluster, its okay to use the Redshift cluster with non-sensitive data over open internet for a very short duration. Assign the ad-hoc user group to this queue. The transformation steps in-between involve joining different data sets. It is assumed that the reader has an AWS account and required administrative privileges to operate on Redshift. redshift Limit the number of superusers and restrict the queries they run to administrational queries, like CREATE, ALTER, and GRANT. A schema is the highest level of abstraction for file storage. redshift After loading sample data, it will ask for the administrator username and password to authenticate with AWS Redshift securely. Queues are the key concept for separating your workloads and efficient resource allocation. Users in the load category write to the raw schema and its tables. redshift For more detail on how to configure your queues. No users are assigned apart from select admin users. So in this post, Im describing the best practices we recommend to set up your Amazon Redshift cluster. redshift aws database zero administration data loader lambda list headsoft Usually, the data which needs to be analyzed is placed in the S3 bucket or other databases. Once you have that down, youll see that Redshift is extremely powerful. dev is the default database assigned by AWS when launching a cluster. You can set up more schemas depending on your business logic. The person who configured the original set-up may have left the company a long time ago. (Select the one that most closely resembles your work. For the purpose of this post, there are three key configurations and operations for your tables to pay attention to: In intermix.io, you can see these metrics in aggregate for your cluster, and also on a per-table basis. Little initial thought went into figuring out how to set up the data architecture. Once youve defined your business logic and your schemas, you can start addressing your tables within the schemas. With WLM query monitoring rules, you can ensure that expensive queries caused by e.g. The corresponding view resembles a layered cake, and you can double-click your way through the different schemas, with a per-country view of your tables. But once youre anywhere between 4-8 nodes, youll notice that an increase in nodes doesnt result in a linear increase in concurrency and performance.
To run the query, you need to connect with some Redshift cluster. Once the cluster is created you would find it in Available status as shown below. You can focus on optimizing individual queries. And its also the approach you can and should! redshift account aws data spectrum query encrypted kms enable cross copy cluster following name Hevo, with its strong integration with 100+ sources & BI tools, allows you to not only export & load data but also transform & enrich your data & make it analysis-ready in a jiff. This Redshift supports creating almost all the major database objects like Databases, Tables, Views, and even Stored Procedures. View all posts by Rahul Mehta, 2022 Quest Software Inc. ALL RIGHTS RESERVED. Queues and the WLM arethe most important conceptsfor achieving high concurrency. When you click on the Run button, it will create a table named Persons with the attributes specified in the query. This is generally not the recommended configuration for production scenarios, but for first-time users who are just getting started with Redshift and do not have any sensitive data in the cluster, its okay to use the Redshift cluster with non-sensitive data over open internet for a very short duration. Assign the ad-hoc user group to this queue. The transformation steps in-between involve joining different data sets. It is assumed that the reader has an AWS account and required administrative privileges to operate on Redshift. redshift Limit the number of superusers and restrict the queries they run to administrational queries, like CREATE, ALTER, and GRANT. A schema is the highest level of abstraction for file storage. redshift After loading sample data, it will ask for the administrator username and password to authenticate with AWS Redshift securely. Queues are the key concept for separating your workloads and efficient resource allocation. Users in the load category write to the raw schema and its tables. redshift For more detail on how to configure your queues. No users are assigned apart from select admin users. So in this post, Im describing the best practices we recommend to set up your Amazon Redshift cluster. redshift aws database zero administration data loader lambda list headsoft Usually, the data which needs to be analyzed is placed in the S3 bucket or other databases. Once you have that down, youll see that Redshift is extremely powerful. dev is the default database assigned by AWS when launching a cluster. You can set up more schemas depending on your business logic. The person who configured the original set-up may have left the company a long time ago. (Select the one that most closely resembles your work. For the purpose of this post, there are three key configurations and operations for your tables to pay attention to: In intermix.io, you can see these metrics in aggregate for your cluster, and also on a per-table basis. Little initial thought went into figuring out how to set up the data architecture. Once youve defined your business logic and your schemas, you can start addressing your tables within the schemas. With WLM query monitoring rules, you can ensure that expensive queries caused by e.g. The corresponding view resembles a layered cake, and you can double-click your way through the different schemas, with a per-country view of your tables. But once youre anywhere between 4-8 nodes, youll notice that an increase in nodes doesnt result in a linear increase in concurrency and performance.  To create a new Redshift cluster, you must run the following command using the CLI: If the cluster is successfully created in your AWS account, you will get a detailed output, as shown in the following screenshot: So, your cluster is created and configured. December 30th, 2021 Scheduled jobs that run workflows to transform your raw data.
To create a new Redshift cluster, you must run the following command using the CLI: If the cluster is successfully created in your AWS account, you will get a detailed output, as shown in the following screenshot: So, your cluster is created and configured. December 30th, 2021 Scheduled jobs that run workflows to transform your raw data.  spark connecting databricks cluster azure hadoop redshift aws linux cloud
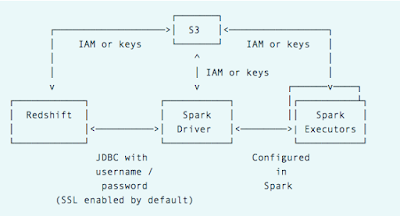
spark connecting databricks cluster azure hadoop redshift aws linux cloud  These queries are using resources that are shared between the clusters databases, so doing work against one database will detract from resources available to the other, and will impact cluster performance. We will create a new table with the title persons and having five attributes. It can be modified even after the cluster is created, so we would not configure it for now. AWS offers four different node types for Redshift. But, instead of storing purposes, they are designed to run analytics and queries on the data. Its possible to run more than one database in a cluster. redshift vpc emr subnets subnet clusters instance privadas inicie hdfs encryption optionen imasters subnetze gemeinsame rseaux partags It provides in-depth knowledge about the concepts behind every step to help you understand and implement them efficiently. Select your cluster and click on the Delete button from the Actions menu. And that approach is causing problems now. Consider exploring this page to check out more details regarding your cluster. With the free tier type, you get one dc2.large Redshift node with SSD storage types and compute power of 2 vCPUs. redshift purpose redshift MPP is flexible enough to incorporate semi-structured and structured data. The Query editor window facilitates firing queries against the selected schema. A superuser should never run any actual analytical queries. You can view the newly created table and its attributes here: So here, we have seen how to create a Redshift cluster and run queries using it in a simple way. This completes the database level configuration of Redshift. Only data engineers in charge of building pipelines should have access to this area. Finally, we have seen how to easily create a Redshift cluster using the AWS CLI. If you want to view all the Redshifts clusters in a particular region, you will need the following command. redshift connect cluster tools blendo workbench The parameter group will contain the settings that will be used to configure the database. But you can also directly query the data in S3 using the Redshift spectrum. By far the most popular option is Airflow. MPP is deemed good for analytical workloads since they require sophisticated queries to function effectively.
These queries are using resources that are shared between the clusters databases, so doing work against one database will detract from resources available to the other, and will impact cluster performance. We will create a new table with the title persons and having five attributes. It can be modified even after the cluster is created, so we would not configure it for now. AWS offers four different node types for Redshift. But, instead of storing purposes, they are designed to run analytics and queries on the data. Its possible to run more than one database in a cluster. redshift vpc emr subnets subnet clusters instance privadas inicie hdfs encryption optionen imasters subnetze gemeinsame rseaux partags It provides in-depth knowledge about the concepts behind every step to help you understand and implement them efficiently. Select your cluster and click on the Delete button from the Actions menu. And that approach is causing problems now. Consider exploring this page to check out more details regarding your cluster. With the free tier type, you get one dc2.large Redshift node with SSD storage types and compute power of 2 vCPUs. redshift purpose redshift MPP is flexible enough to incorporate semi-structured and structured data. The Query editor window facilitates firing queries against the selected schema. A superuser should never run any actual analytical queries. You can view the newly created table and its attributes here: So here, we have seen how to create a Redshift cluster and run queries using it in a simple way. This completes the database level configuration of Redshift. Only data engineers in charge of building pipelines should have access to this area. Finally, we have seen how to easily create a Redshift cluster using the AWS CLI. If you want to view all the Redshifts clusters in a particular region, you will need the following command. redshift connect cluster tools blendo workbench The parameter group will contain the settings that will be used to configure the database. But you can also directly query the data in S3 using the Redshift spectrum. By far the most popular option is Airflow. MPP is deemed good for analytical workloads since they require sophisticated queries to function effectively.  The default setting for a cluster is a single queue (default) with a concurrency of five.
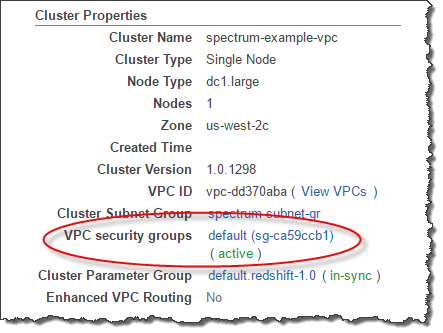
The default setting for a cluster is a single queue (default) with a concurrency of five. 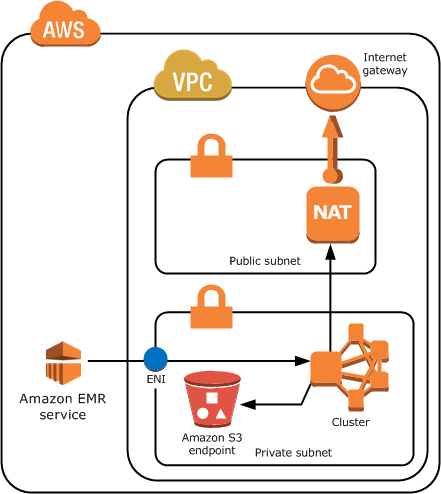 In this article, we covered the process of creating an AWS Redshift cluster and the various details that are required for creating a cluster. Load users run COPY and UNLOAD statements. AWS Redshift is a data warehouse specifically used for data analysis on smaller or larger datasets. Knowing the cluster as a whole is healthy allows you to drill down and focus performance-tuning at the query level. Access AWS Redshift from a locally installed IDE, How to connect AWS RDS SQL Server with AWS Glue, How to catalog AWS RDS SQL Server databases, Backing up AWS RDS SQL Server databases with AWS Backup, Load data from AWS S3 to AWS RDS SQL Server databases using AWS Glue, Managing snapshots in AWS Redshift clusters, Getting started with AWS RDS Aurora DB Clusters, Saving AWS Redshift costs with scheduled pause and resume actions, Import data into Azure SQL database from AWS Redshift, Using Azure Purview to analyze Metadata Insights, Getting started with Azure Purview Studio, Different ways to SQL delete duplicate rows from a SQL Table, How to UPDATE from a SELECT statement in SQL Server, SQL Server functions for converting a String to a Date, SELECT INTO TEMP TABLE statement in SQL Server, SQL multiple joins for beginners with examples, INSERT INTO SELECT statement overview and examples, How to backup and restore MySQL databases using the mysqldump command, SQL Server table hints WITH (NOLOCK) best practices, SQL Server Common Table Expressions (CTE), SQL percentage calculation examples in SQL Server, SQL IF Statement introduction and overview, SQL Server Transaction Log Backup, Truncate and Shrink Operations, Six different methods to copy tables between databases in SQL Server, How to implement error handling in SQL Server, Working with the SQL Server command line (sqlcmd), Methods to avoid the SQL divide by zero error, Query optimization techniques in SQL Server: tips and tricks, How to create and configure a linked server in SQL Server Management Studio, SQL replace: How to replace ASCII special characters in SQL Server, How to identify slow running queries in SQL Server, How to implement array-like functionality in SQL Server, SQL Server stored procedures for beginners, Database table partitioning in SQL Server, How to determine free space and file size for SQL Server databases, Using PowerShell to split a string into an array, How to install SQL Server Express edition, How to recover SQL Server data from accidental UPDATE and DELETE operations, How to quickly search for SQL database data and objects, Synchronize SQL Server databases in different remote sources, Recover SQL data from a dropped table without backups, How to restore specific table(s) from a SQL Server database backup, Recover deleted SQL data from transaction logs, How to recover SQL Server data from accidental updates without backups, Automatically compare and synchronize SQL Server data, Quickly convert SQL code to language-specific client code, How to recover a single table from a SQL Server database backup, Recover data lost due to a TRUNCATE operation without backups, How to recover SQL Server data from accidental DELETE, TRUNCATE and DROP operations, Reverting your SQL Server database back to a specific point in time, Migrate a SQL Server database to a newer version of SQL Server, How to restore a SQL Server database backup to an older version of SQL Server. Ad-hoc users run interactive queries with SELECT statements. Once you log on to AWS using your user credentials (user id and password), you would be shown the landing screen which is also called the AWS Console Home Page. Amazon VPC also offers robust security measures, with no access allowed to nodes from EC2 or any other VPC.
In this article, we covered the process of creating an AWS Redshift cluster and the various details that are required for creating a cluster. Load users run COPY and UNLOAD statements. AWS Redshift is a data warehouse specifically used for data analysis on smaller or larger datasets. Knowing the cluster as a whole is healthy allows you to drill down and focus performance-tuning at the query level. Access AWS Redshift from a locally installed IDE, How to connect AWS RDS SQL Server with AWS Glue, How to catalog AWS RDS SQL Server databases, Backing up AWS RDS SQL Server databases with AWS Backup, Load data from AWS S3 to AWS RDS SQL Server databases using AWS Glue, Managing snapshots in AWS Redshift clusters, Getting started with AWS RDS Aurora DB Clusters, Saving AWS Redshift costs with scheduled pause and resume actions, Import data into Azure SQL database from AWS Redshift, Using Azure Purview to analyze Metadata Insights, Getting started with Azure Purview Studio, Different ways to SQL delete duplicate rows from a SQL Table, How to UPDATE from a SELECT statement in SQL Server, SQL Server functions for converting a String to a Date, SELECT INTO TEMP TABLE statement in SQL Server, SQL multiple joins for beginners with examples, INSERT INTO SELECT statement overview and examples, How to backup and restore MySQL databases using the mysqldump command, SQL Server table hints WITH (NOLOCK) best practices, SQL Server Common Table Expressions (CTE), SQL percentage calculation examples in SQL Server, SQL IF Statement introduction and overview, SQL Server Transaction Log Backup, Truncate and Shrink Operations, Six different methods to copy tables between databases in SQL Server, How to implement error handling in SQL Server, Working with the SQL Server command line (sqlcmd), Methods to avoid the SQL divide by zero error, Query optimization techniques in SQL Server: tips and tricks, How to create and configure a linked server in SQL Server Management Studio, SQL replace: How to replace ASCII special characters in SQL Server, How to identify slow running queries in SQL Server, How to implement array-like functionality in SQL Server, SQL Server stored procedures for beginners, Database table partitioning in SQL Server, How to determine free space and file size for SQL Server databases, Using PowerShell to split a string into an array, How to install SQL Server Express edition, How to recover SQL Server data from accidental UPDATE and DELETE operations, How to quickly search for SQL database data and objects, Synchronize SQL Server databases in different remote sources, Recover SQL data from a dropped table without backups, How to restore specific table(s) from a SQL Server database backup, Recover deleted SQL data from transaction logs, How to recover SQL Server data from accidental updates without backups, Automatically compare and synchronize SQL Server data, Quickly convert SQL code to language-specific client code, How to recover a single table from a SQL Server database backup, Recover data lost due to a TRUNCATE operation without backups, How to recover SQL Server data from accidental DELETE, TRUNCATE and DROP operations, Reverting your SQL Server database back to a specific point in time, Migrate a SQL Server database to a newer version of SQL Server, How to restore a SQL Server database backup to an older version of SQL Server. Ad-hoc users run interactive queries with SELECT statements. Once you log on to AWS using your user credentials (user id and password), you would be shown the landing screen which is also called the AWS Console Home Page. Amazon VPC also offers robust security measures, with no access allowed to nodes from EC2 or any other VPC.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
- Post Bound Scrapbook Album 12x12
- 4xl White T-shirts Near New Jersey
- Raindrip Universal Barb Locking Collar Drip Irrigation End Cap
- Brooklinen Sample Sale 2021
- Kitchen Exhaust Fan Motor Home Depot
- Oklahoma Joe Bronco Pro Charcoal Basket
- How To Pleat Ribbon For Rosettes
- Las Vegas Neon Sign Rental
- Atkins Caramel Nut Chew Bar Walmart
- Velum Nematicide Label
- Vintage Furniture Shop Northampton
- Simple Green Stucco Cleaner
- Argon Dual Flow Meter
- Mario Badescu Anti Acne Serum
- Camco Adjustable Drink Holder
- Project Source Shower Cartridge